KyteStore 技术白皮书
KyteStore 是面向湖仓系统和 AI 训推场景的透明加速存储底座。它在统一的 ChunkServer 数据层之上提供 S3 兼容对象协议和 POSIX 文件语义,让用户可以在不重写业务系统的前提下,把热数据留在本地高速介质,把远端 S3/COS/OSS 作为容量层和回源层。
1. 概览
解决的问题
湖仓引擎、分析数据库、AI 训练任务和推理服务经常同时访问远端对象存储。直接访问 S3/COS/OSS 的优势是容量弹性和低运维成本,但在高频小对象、热数据反复读取、checkpoint 写入、数据集扫描等场景中,远端访问会带来延迟、带宽成本和吞吐抖动。
KyteStore 在业务系统和远端对象存储之间增加一层本地分布式加速层。用户仍然使用熟悉的 S3 Endpoint 或文件路径,底层由 KyteStore 负责路由、本地缓存、写缓冲、多副本保护、异步回刷和故障恢复。
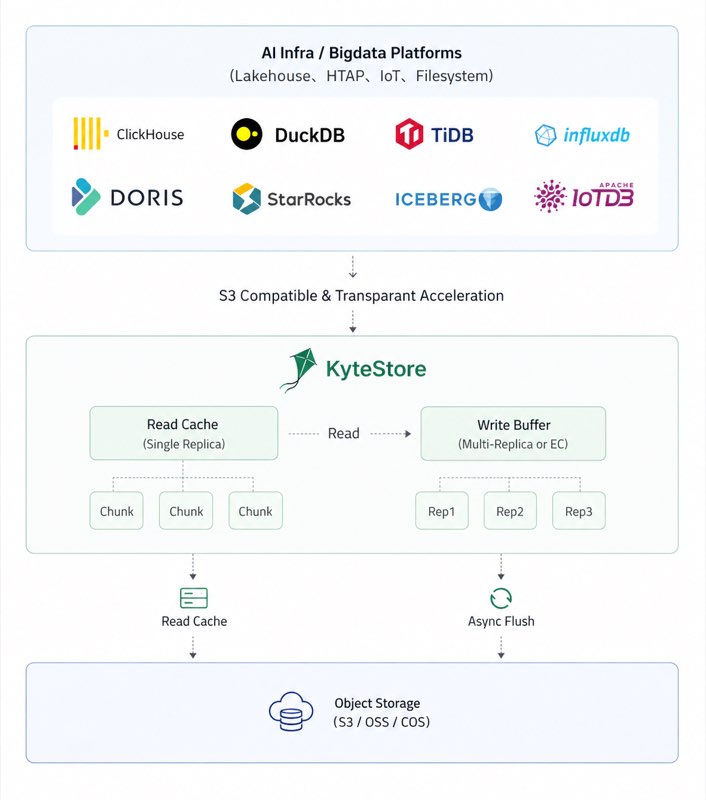
典型场景
湖仓查询加速
ClickHouse、Doris、DuckDB、StarRocks 等系统可以把 KyteStore 当作 S3 Endpoint,降低热点对象读取延迟,并减少远端对象存储带宽消耗。
AI 数据集访问
训练和推理任务可以通过 POSIX/FUSE 语义读取数据集、模型文件和中间结果,让已有脚本保留路径访问方式。
写入与 checkpoint
高频写入先落到本地 Write Buffer,用户可以写后即读,后台再异步同步到远端对象存储。
能力地图
| 能力 | 用户价值 | 核心机制 |
|---|---|---|
| S3 兼容对象访问 | 替换远端对象存储 Endpoint,不改变湖仓和分析系统接入方式。 | FE S3GatewayService + KyteS3SDK + DS S3SubSystem。 |
| POSIX 文件语义 | 让 AI 程序通过路径、目录、文件句柄和 rename 语义访问存储。 | PosixGatewayService + DS FSSubsystem 元数据分片。 |
| 本地读缓存 | 把热点对象切片落到本地 SSD,降低重复读取延迟。 | Read Cache Namespace、LocalMetaKV、ChunkSubSystem。 |
| 写缓冲加速 | 写入先提交到本地多副本,后台异步刷回 S3,支持写后即读。 | Write Buffer Namespace、ObjectMetaIndex、BufferedObjectSyncManager。 |
| 多副本和高可用 | 写入数据不依赖单个节点,异常时可恢复和迁移。 | Chunk 多副本、Primary/Secondary 写入复制、Slot Recovery。 |
部署和使用
KyteStore 可以从单机模拟集群开始验证,也可以按 FE、DataServer、MetaServer、FoundationDB 控制面和本地 SSD 资源拆分为生产集群。用户侧接入时不需要改写业务逻辑:湖仓和分析系统继续使用 S3 Endpoint,AI 训练和推理任务继续使用文件路径,底层由 KyteStore 负责本地 SSD 加速、多副本保护和远端 S3 同步。
单机部署配置建议
单机部署适合 PoC、功能验证、开发测试和小规模低并发使用。此模式通常把 FE、DS、MS 和 FDB 放在同一台服务器上,部署简单,但不建议作为高可用生产架构。
| 档位 | CPU | 内存 | SSD | 网络 | 适用场景 |
|---|---|---|---|---|---|
| 最低配置 | 8 vCPU | 32 GiB | 500 GB SSD | 1 Gbps | 功能验证、开发测试、低并发 PoC。 |
| 推荐配置 | 16 vCPU | 64 GiB | 1 TB NVMe | 10 Gbps | 小规模正式使用、稳定读写加速。 |
| 性能配置 | 32 vCPU | 128 GiB | 2-4 TB NVMe | 25 Gbps | 更高并发、较大缓存、持续写入场景。 |
集群部署配置建议
生产环境建议把数据面和控制面分开规划。FE 负责 S3/文件协议入口和请求路由,DS 负责本地缓存、写缓冲、ChunkServer 多副本和文件元数据热路径,MS/FDB 负责集群控制面和全局元数据。
| 档位 | 典型拓扑 | FE 节点规格 | DS 节点规格 | 网络 |
|---|---|---|---|---|
| 最低配置 | 1 FE + 2 DS + 1 控制面 | 4 vCPU / 8 GiB / 100 GB SSD | 8 vCPU / 32 GiB / 1 TB SSD | 10 Gbps |
| 推荐配置 | 2 FE + 3 DS + 3 控制面 | 8 vCPU / 16 GiB / 100 GB SSD | 16 vCPU / 64 GiB / 2 TB NVMe | 10-25 Gbps |
| 性能配置 | 2-4 FE + 6+ DS + 3 控制面 | 16 vCPU / 32 GiB / 200 GB SSD | 32 vCPU / 128 GiB / 4+ TB NVMe | 25 Gbps+ |
对象和文件接入方式
| 接入方式 | 用户侧改动 | 推荐模式 | 关键说明 |
|---|---|---|---|
| S3 兼容对象协议 | 把湖仓、查询引擎或 S3 SDK 的 Endpoint 指向 KyteStore FE。 | read_cache 或 read_write / mixed。 | 适合 ClickHouse、Doris、DuckDB、StarRocks 等系统读取热对象,也适合写入后需要快速读回的 checkpoint 或中间结果。 |
| POSIX 文件语义 | 通过 POSIX/FUSE 入口挂载到业务机器,应用继续使用路径、目录和文件 API。 | local_only 或 mixed。 | 适合 AI 训练、推理、脚本任务和小文件元数据密集场景;文件数据仍复用底层 ChunkServer 写入和缓存能力。 |
| 远端 S3 数据层 | 配置后端 S3/COS/OSS bucket 和凭证,或通过请求级 Header 传入后端身份。 | mixed。 | 本地 SSD 承担热数据和写缓冲,远端对象存储承担容量层和长期存储,适合成本敏感业务。 |
- DS 是资源消耗最大的角色,CPU、内存和本地 NVMe 性能会直接影响缓存命中、写缓冲和文件元数据吞吐。
- 控制面建议至少准备 3 个 FDB coordinator;MS 可以与其中一台控制面节点同机部署。
- 写入加速场景优先增加 DS 数量和本地盘容量;接入和转发压力更高时再增加 FE 节点。
2. 整体架构
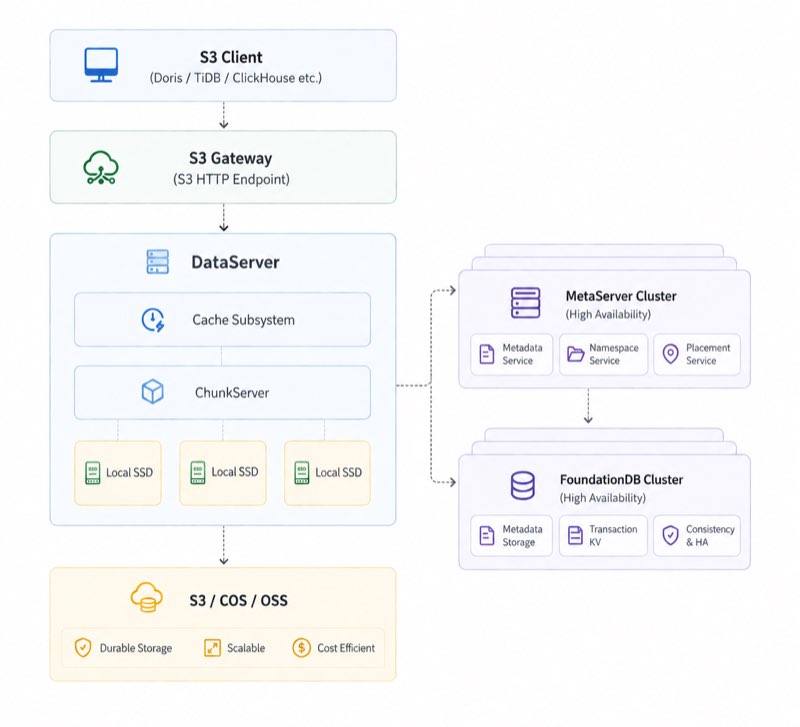
ChunkServer
在大规模分布式存储系统中,ChunkServer 通常承担统一数据底座的角色:上层系统维护对象、文件、目录或表分片的元数据,底层 ChunkServer 负责把真实数据追加写入较大的连续数据单元,并处理本地磁盘布局、副本复制、seal、repair 和容量回收。这样做的价值是把协议语义和物理数据管理解耦,上层可以快速演进,底层则稳定优化吞吐、延迟和可靠性。
业内很多系统都有类似分层。以 ByteStore、Azure Storage 这类架构为例,上层负责对象索引、分区路由或 namespace 管理,底层存储层把数据聚合为 chunk / extent 一类的复制单元;Azure Storage 公开论文中的 Stream Layer 使用 Stream Manager 与 Extent Node 管理 extent,extent 是复制、seal 与后台修复的重要单位。KyteStore 借鉴的是这种“上层语义轻量化、底层数据单元统一化”的工程思路,而不是为每一种协议重复实现一套存储引擎。
小对象与小文件聚合
KyteStore 不把每个小对象或小文件直接映射成独立磁盘文件,而是把对象 part、文件 extent 或缓存 slice append 到 Chunk 中。上层元数据记录 key / inode 到 chunk_id、offset、length 的映射,本地盘看到的是更大、更顺序的写入单元。
多副本转发
MetaServer 为 Chunk 选择 Primary 和 Secondary 副本。前台写入先进入 Primary,Primary 在本地 append 后按同一 offset 转发给 Secondary;ChunkInfo 记录 server_ids 和目标副本数,repair worker 后续补齐缺失副本。
这也是 KyteStore 支持多协议的关键。S3 Subsystem、FS Subsystem 以及后续 HDFS/NFS/SDK 接入层只需要处理各自的命名空间、权限、元数据和语义差异;真正的数据写入、读缓存、写缓存、多副本、seal、repair、GC 和冷热分离都复用同一套 ChunkServer。新的上层系统接入时,不需要重新设计底层可靠写入和本地盘管理,只需要把自身语义映射到统一的 chunk 数据模型。
核心角色
| 角色 | 职责 | 用户侧影响 |
|---|---|---|
| FE | S3 HTTP 网关、未来 POSIX/FUSE 网关、启动 readiness、请求路由入口。 | 提供稳定 Endpoint,屏蔽 DS 拓扑变化。 |
| MetaServer | 持久化全局元数据,管理 DataServer、ChunkGroup、S3 Namespace、Slot Topology 和 FS owner epoch。 | 提供一致的控制面,不进入普通对象读写热路径。 |
| DataServer | 实际数据读写、对象读缓存、写缓冲、文件元数据服务、本地 Chunk 管理。 | 承载吞吐和延迟,随着节点数横向扩展。 |
| Remote S3 | 容量层、回源层和最终对象存储后端。 | 保留云对象存储的容量弹性和跨系统可访问性。 |
存储模式
3. 对象加速
S3 网关
FE 的 S3GatewayService 提供 Path-style S3 HTTP 入口,解析 HTTP Method、URI、bucket、object key、Range、分页参数和请求级凭证。FE 不再在对象 API 热路径直连后端 S3,而是统一通过 KyteS3SDK 转发到 DS,由 DS 负责 read-through、write-buffer、LIST merge、delete propagation 和 cache invalidation。
后端凭证可以来自 FE 固定配置,也可以通过 x-kyte-s3-* 请求 Header 传入,便于一个 KyteStore Endpoint 代理不同云厂商或不同 bucket 的后端身份。
读缓存路径
读缓存的核心是切片和去重。SDK 将大对象范围读切成多个 slice,按 slot 路由到对应 DS。DS 先查本地 CacheIndex;缓存未命中时通过 CacheLoadTaskShard 避免同一范围被多个请求重复回源。
写加速 Write Buffer
写路径使用独立的 Write Buffer Namespace。PutObject 和 Multipart Upload 的数据先写入 DS 本地 Chunk,并由 ChunkSubSystem 执行多副本同步;对象被 Seal 后立即对后续 GET/HEAD/LIST 可见,后台 S3 sync 再把数据上传到远端对象存储。
S3 API 覆盖
| API | 状态 | 说明 |
|---|---|---|
| GetObject / Range GET | 已实现 | 支持整对象和 Range 读取,显式 offset-range 不要求先 HEAD。 |
| PutObject | 已实现 / 持续增强 | read_write 与 local_only 写入 Write Buffer;read_cache 模式可代理远端直写。 |
| HeadObject / ListObjectsV2 | 已实现 | 合并本地 write-buffer 和远端对象视图,返回对象元信息和分页列表。 |
| DeleteObject / DeleteObjects | 已实现 | 支持 tombstone、read-cache invalidation 和远端删除传播。 |
| Multipart Upload | 已实现 / 持续增强 | UploadPart 映射为 AppendObject,CompleteMultipartUpload 映射为 SealObject。 |
4. 文件加速
POSIX 语义定位
FSSubsystem 面向 AI / 大模型工作负载,不试图在第一阶段覆盖完整通用文件系统语义。优先级最高的是 dataset 读取、checkpoint 顺序写、临时文件 close 后 rename 发布、目录遍历、小文件 metadata 批处理和 close-to-open 可见性。
kyte-fuse 或 FS SDK 运行在客户端机器上;FE 提供 PosixGatewayService,负责鉴权、mount session、拓扑发现和兼容入口;长期高性能路径可以通过 FS SDK 缓存拓扑后直连 DS。
元数据模型
文件元数据不放在 MetaServer/FDB 的普通热路径里。MS/FDB 负责 FS binding、bucket owner map、epoch、checkpoint pointer 和 inode range allocation;dentry、inode attr、extent map 由 DS FSSubsystem 的 inode bucket owner 负责。
逻辑上,目录本身也是一个 inode。目录的可见命名空间由一组 dentry 组成,每条 dentry 的 key 是 <parent_inode, name>,value 指向 child inode。child inode 再保存文件类型、属性、link count、size,以及指向底层 chunk 的 extent map。目录并不直接绑定到某个 DS,而是维护自己的 DirectoryLayout,用来把文件名 hash range 映射到一个或多个 inode buckets。
访问路径分两步:第一步由 bucket_index = hash(parent_inode, filename, seed) % inode_bucket_size 找到目录内的逻辑 bucket_index;第二步由 DirectoryLayout 把 bucket_index 映射到 inode_bucket_id,再通过全局 owner map 找到 DS。create 在命中的 inode bucket 内写入 dentry,并从该 bucket 的 inode range 中分配 child inode。
因此,目录 split 和 DS owner 迁移是两类不同操作:目录 split 调整 DirectoryLayout 中的 hash range 到 inode_bucket_id 映射;故障切换或 rebalance 调整 inode_bucket_id 到 owner DS 的映射。用户看到的路径语义不变,但系统可以独立扩展大目录和迁移故障节点。
这种设计避免每次 create/open/list 都访问 MS/FDB,让 metadata 热路径可以随 DS inode bucket 横向扩展。MS/FDB 仍然作为控制面存在,保证 owner fencing、checkpoint 定位和迁移恢复。
FS API
| 接口组 | 代表 RPC | 语义 |
|---|---|---|
| 生命周期与探测 | Probe | 查询 DS FSSubsystem 是否初始化、启动以及当前 FsStorageBinding。 |
| 目录与文件元数据 | Mkdir, CreateFile, Lookup, GetAttr, Readdir, Unlink, Rmdir | 以 inode 和 parent/name 形式操作目录项和 inode 属性。 |
| 路径兼容接口 | LookupPath, MkdirPath, CreateFilePath, ReaddirPath, UnlinkPath, RmdirPath | 提供面向网关和调试的路径级操作,内部仍会落到 inode/bucket 路由。 |
| 布局与恢复 | GetDirectoryLayout, MaterializeDentryBucket, RecoverInodeBucket | 管理目录 bucket、虚拟到物理 bucket 映射和 inode bucket 恢复。 |
5. 一致性与高可用
Slot 映射与拓扑 Fence
S3 Namespace 被划分为固定数量的 slot。SDK 按 object key 计算 slot,并根据 MetaServer 提供的 namespace topology 找到 owner DS。请求携带 slot_id 和 topo_version,DS 用本地缓存的 topology 校验请求是否路由到了正确 owner。
恢复与维护
KyteStore 的恢复机制围绕 owner、manifest、sealed object metadata 和本地 MetaKV 状态构建。DS 可上报 LocalMetaKV 状态,MetaServer 提供 sealed manifest 和 candidate chunk 查询,维护接口支持进入用户 IO 维护模式、查看 slot recovery 状态、诊断对象范围和必要时 force reset failed slot。
可见性语义
| 场景 | 语义 | 实现要点 |
|---|---|---|
| 对象写后即读 | PutObject 或 SealObject 成功后,GET/HEAD/LIST 优先读取 write-buffer 当前版本。 | ObjectMetaIndex、generation、read-cache invalidation。 |
| 对象缓存失效 | 写入、删除、完成 MPU 改变可见版本后,失效 read-cache 旧切片。 | DS 内部 ReadCacheInvalidator,必要时跨 DS 调用 InvalidateObjectCache。 |
| 文件 close-to-open | 写入对其他客户端的可见点优先定义在 Flush/Fsync/Release 或同目录 Rename 后。 | FS metadata WAL、extent commit、rename 原子语义。 |
6. API 与运维
管理与诊断接口
控制面通过 MetaServer 管理 namespace、slot migration、capacity、usage、manifest recovery 和 route resolve;数据面通过 DS admin service、S3SubSystem admin service 和 FSSubsystem service 暴露健康、使用量、维护、诊断和文件元数据接口。
| 接口族 | 代表能力 | 使用场景 |
|---|---|---|
| MetaServer S3 Admin | Create/List/Delete Namespace、SlotMigrate、ResolveObjectRoute、ListS3NamespaceSpaceUsage | 创建加速空间、查看容量、迁移 slot、排查对象路由。 |
| S3SubSystem Admin | GetNamespaceUsage、Enter/Leave Maintenance、ListSlotRecoveryStatus、DiagnoseObjectRange | 节点级维护、恢复状态检查、对象范围诊断。 |
| ChunkSubSystem Client | AllocateChunk、AppendChunk、ReadChunk、SealChunk、RepairChunkReplica | 内部数据路径和副本修复,不直接暴露给普通用户。 |
| FSSubsystem Service | Lookup、CreateFile、Readdir、GetDirectoryLayout、RecoverInodeBucket | 文件语义、目录布局、inode bucket 恢复。 |
监控指标
KyteStore 使用 brpc metrics 暴露 MS/DS 指标,并提供 Prometheus + Grafana 方案。MetaServer 还提供 namespace 级空间用量查询,用于控制台和运维脚本展示用户视角容量、逻辑占用、副本因子、chunk 摘要和估算边界。
部署形态
KyteStore 单个二进制可以通过 --start_mode=metaserver 或 --start_mode=dataserver 启动不同角色。最小单机模拟集群适合 PoC、功能验证和 benchmark;生产部署建议拆分 MetaServer、DataServer、本地 SSD、FoundationDB 和监控栈。
7. 性能与调优
对象性能
当前官网首页已经展示对象加速的基础吞吐、基础延迟和 TPCDS 数据。代码侧性能分析进一步显示,64KB GET 的 FE HTTP E2E 延迟可以拆为 FE、SDK、DS local MetaKV、read_chunk 和 response path 等阶段;高并发 PUT 的瓶颈更多受本地盘 64KB direct append 能力影响。
文件性能
文件加速性能将按 metadata 与 data read/write 分开度量。metadata 侧重点包括 Lookup、CreateFile、Readdir、Rename/Unlink 和 inode bucket recovery;data 侧重点包括 dataset 顺序读取、checkpoint 顺序写、close-to-open 可见点和 extent commit。
调优方向
- 对象读路径关注 slice_length、cache hit ratio、LocalMetaKV 延迟、本地 SSD 读延迟和远端 S3 回源耗时。
- 对象写路径关注 write-buffer 副本数、本地盘 O_DIRECT append 能力、chunk soft limit、异步 S3 sync backlog。
- 文件路径关注目录 bucket 数、inode bucket owner 分布、metadata WAL group commit、checkpoint 周期和 list fanout。
- 集群维度关注 slot owner 均衡、topo_version 收敛、DS 维护窗口、missing replica count 和 namespace capacity 水位线。